

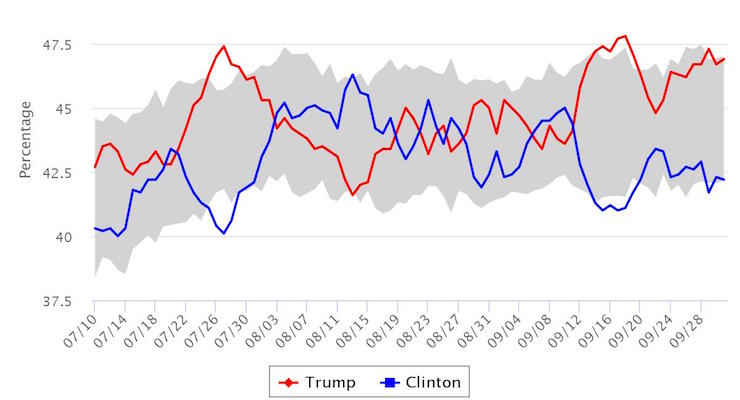
The 2016 USC Dornsife / LA Times Presidential Election Poll for October 2, 2016: Republican Donald Trump vs. Democrat Hillary Clinton. (Photo: THE USC DORNSIFE / LA TIMES PRESIDENTIAL ELECTION “DAYBREAK” POLL)
After nearly a week of interviews conducted after the first presidential debate, Donald Trump leads Hillary Clinton by roughly 5 points in the LA Times Poll, 46.9% to 42.2%. TV pundits have stuck to conventional political wisdom, despite the fact it has failed them at every turn this election cycle.
As a result, the LA Times Poll has been taking even more heat than it has in the previous several weeks, which is really saying something.
Last week, during an appearance on Fox News, Larry Sabato, whom we respect (so save your emails), insinuated “random sample polls” have shown an impact from the debate that favors Mrs. Clinton. It was an indirect dig at the LA Times Poll–and, the People’s Pundit Daily U.S. Presidential Election Daily Tracking Poll for that matter–a dig that has been repeated on Twitter by others like Sean Trende at Real Clear Politics.
But there’s something pretty damn significant missing from the conventional wisdom-based argument, something I think readers and election-watchers should know. In 2012, the model and methodology they are using, which was designed by the team behind the RAND Continuous Presidential Election Poll, or the “Daybreak Poll,” which was accurate when most other traditional random sample polls were not.
But that’s not it. It’s the reason why the model was right that is of particular significance to this election cycle. Let’s take a look at how they polled the 2012 presidential election between President Barack Obama and Gov. Mitt Romney, and their results.
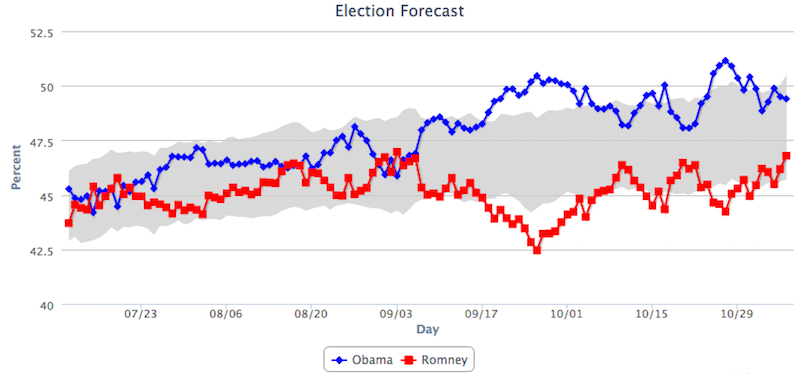
Source: Rand Corporation
As you can see from the graph above, the “Daybreak Poll” only temporarily had the former Republican nominee in the lead at the beginning of the month of September. Why is this significant? Because following the first presidential debate moderated by Jim Lehrer, a debate the pundits and conventional political wisdom all agreed Gov. Romney won handily, random sample polls found President Obama trailing by roughly 2 to 7 points.
For instance, a Pew Research Center survey, which was conducted from October 4 to October 7, found Mr. Obama trailing Mr. Romney by 4 points, 45% to 49%. In the Daybreak Poll, Mr. Romney never led during that period and, in fact, was down by roughly 4 points during that very week, nearly the same margin he would go on to lose the election by. The week before the election, 2 random sample polls found Mr. Obama behind by 1 point, another 2 had him up by 1 point and just 1 had him up by 3.
Another 3 polls conducted the final week had the race tied, with Gov. Romney leading among the most likely of voters.
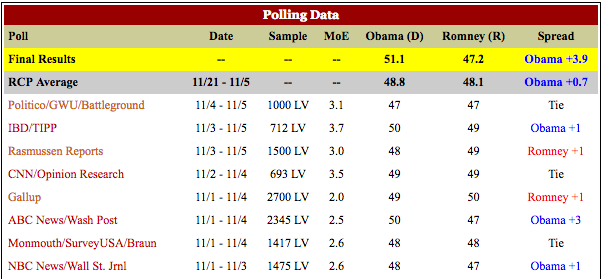
Source: Real Clear Politics
NeverTrump Republican pollster Ed Goeas, who conducted the final GW Battleground Poll for Politico in 2012, argued that he believed many who said they were likely to vote would not.
Among the 80 percent of those surveyed who he believes are most likely to actually vote, Romney leads by 3 points, 51 percent to 48 percent. Among the 70 percent he believes are most likely, Romney leads by 2 points, 51 percent to 49 percent.
“So in no case at any level does Obama break that 50 percent mark,” Goeas said the Tuesday of the presidential election. “I think you’re probably looking at a 2-point Romney win at this point … Then the question becomes: What about the Electoral College?”
Well, we now know Mr. Goeas, as well as many other “Gold Standard” pollsters, were flatly wrong. Mr. Obama’s voters did come out to vote, while millions upon millions of GOP-leaning voters, many of the very same voters prone to Mr. Trump’s nationalist message, stayed home and did not.
In 2014, many of these same pollsters overcorrected, and shocker, they were wrong again. We were not. Why? Because we recognized that pollsters in 2012, and again in 2014, seemed to be having a difficult time reading the electorate, specifically participants who were most likely to vote. To put it simply, many pollsters’ likely voter models are broken and we find it rich–to put it nicely–that these are the same voices criticizing the LA Times Poll.
In 2012, they defended the disparity of their results by stating their model “allows us to ask the same people for their opinion repeatedly over time,” which “leads to much more stable outcomes; changes that we see are true changes in people’s opinions and not the result of random fluctuations in who gets asked the questions.”
Basically, if you can identify and track a representative sample of truly undecided voters–those who will ultimately decide the outcome of the election–than you can more accurately predict that outcome. They were trying to effectively minimize their exposure to what causes sampling errors in random samples while at the same time more correctly identify those who were most likely to vote.
They argued they “may be more accurately capturing the likely votes of a greater number of voters in the crucial ‘middle’ by allowing respondents to more precisely assign their own numerical probability (or percent chance) to both the likelihood that they will vote and the likelihood that they will vote for a particular candidate.”
We’re not saying that random sample polls are a thing of the past, but we are, I am, saying that it may be time for them to evolve. More importantly, I am saying that it is intellectually dishonest to dismiss the findings of someone who was right, particularly when you were wrong. Perhaps, just perhaps, it isn’t the case the LA Times Poll has a “built-in” Trump bias, as Trende and others have suggested. Perhaps, just perhaps, the others have a built-in Clinton bias.
Perhaps the LA Times Poll is accurately capturing the indisputable fact that Trump voters are far more likely to vote than Clinton voters, something the latest NBC News/Wall Street Journal Poll did in fact dispute.
“By comparison,” they wrote in 2012, “traditional polls may not be fully capturing the intentions of these voters because they rely on less precise qualitative metrics (such as somewhat likely and somewhat unlikely) when asking respondents to indicate for whom they may vote and the likelihood that they will vote.”
They were mocked in 2012, as well.
Without giving away in-house trade secrets that made us the most accurate election forecast model in 2014, the People’s Pundit Daily U.S. Presidential Election Daily Tracking Poll is somewhat of a hybrid. We recognized the potential of the model in 2014, incorporated what we thought we should and it paid off. Meanwhile, traditional pollsters were almost universally wrong.
So, in closing, when I see the LA Times Poll markedly more pro-Trump than our own at PPD, I recognize that it would be an act of hubris to outright dismiss it.
(UPDATE: A Twitter user sent this study from Columbia to me after reading the article. It backs up the Rand model and explains in greater detail the point I was trying to make. Essentially, the wild swings shown by pollster never really happened in 2012, but rather were “artifacts” of the polls themselves and their sample errors. I largely agree.)






Stephen Reed ✓ᵀᴿᵁᴹᴾ / October 2, 2016
Watching the Clinton debate bump recede – as of 10/1/2016 results, Clinton is +0.6.
/
Just(R)ight. / October 2, 2016
If you want an accurate poll, just compare Trump’s rally attendance vs Hillary’s rally attendance.
Hillary has almost ZERO enthusiasm out there.
/
Ryan T / October 3, 2016
@PPDNews good discussion. Thanks 4 writing.
/
Healthnut / October 3, 2016
You will either be the heroes or the laughable goats.
If you have Trump +4 and he wins by around +4, and everyone else has Hillary winning, you will have revolutionized the polling business.
/
Earn_Your_Freedom / October 7, 2016
This is what happened in 2012 with Romney and Obama. This poll was correct about Obama winning. All the others were wrong. Was it revolutionary then? Not diminishing your post – it’s more of an objective comment about the state of information outlets (media and polling) and whether or not they are trying to push the public at large to either vote or not vote, sway or not sway. For example, there is a good amount of speculation that early (skewed likely) reporting from the east coast during the Reagan-Carter elections that Reagan was far besting Carter actually influenced west coast voters. If enough of these “legit” polls show HRC constantly and substantially in the lead, will it cause some people to say “forget it, it’s over, she won. why should I get off my couch and vote at all” ? Could this be something similar but a more prolonged and controlled exercise…?
/
Karl Marx / September 11, 2020
Any questions now?
/
JacksonPackson / October 4, 2016
@PPDNews Do Trump supporters have any legitimate reason to fear the entire election being rigged?
/
john awe / October 13, 2016
Yes.
/
Trương Thành Đạt / October 4, 2016
WE think you are right ppd.
Love from florida!
/
Whit_Chambers / October 4, 2016
Good article. Thanks!
/
john awe / October 13, 2016
Very intelligent and well written article. Thank you. Nice to have facts instead of propaganda from the rest of the lying media.
/
David / October 18, 2016
LA Time/USC Poll is created by the smartest people at USC. It is the best Poll money can buy. It will decide who our next President will be.
/
Dave E / November 9, 2016
With Trump President elect, the L.A. Times Poll apparently isn’t such a joke is it? They’ve had Trump ahead in the polls consistently through September & October, and got mocked relentlessly by pundits.
/